Unicode 正规形式
本文最后更新于 515 天前(2021-12-22),其中的信息可能已经有所发展或者不再适用于现阶段。
本文全长 682 字,全部读完大约需要 2 分钟。
之前遇到从某音乐网站上复制的歌名和其他网站上不相等的情况:像这样,
let a = "ELISA-Dear My Friend -まだ見ぬ未来へ-.jpg"
let b = "ELISA-Dear My Friend -まだ見ぬ未来へ-.jpg"
console.log(a === b)
用肉眼看不出它们的区别,保存成文件名也会保存出两个不同的,通过 URL 访问也不会互相命中,很是让我困惑。
最近发现了原因,Unicode 定义了 4 种正规形式,分别是
| 缩写 | 名称 | 含义 |
|---|---|---|
| NFC | Normalization Form Canonical Composition | 以标准等价方式分解,然后以标准等价方式组合 |
| NFD | Normalization Form Canonical Decomposition | 以标准等价方式分解 |
| NFKC | Normalization Form Compatibility Composition | 以兼容等价方式分解,然后以标准等价方式组合 |
| NFKD | Normalization Form Compatibility Decomposition | 以兼容等价方式分解 |
比如说 Å 这个符号,既可以表示为单个 BMP 字符 U+00C5,也可以表示为一个代理对 U+0041U+030A。其中单个字符 U+00C5 是它的 NFC 正规形式,而 U+0041U+030A 则是 NFD 正规形式。
日语中的浊点(゛)也具有这样的性质,可以表示为组合形式或分解形式。根据我的测试,我们用输入法打出来的通常都是组合形式 NFC,如图:
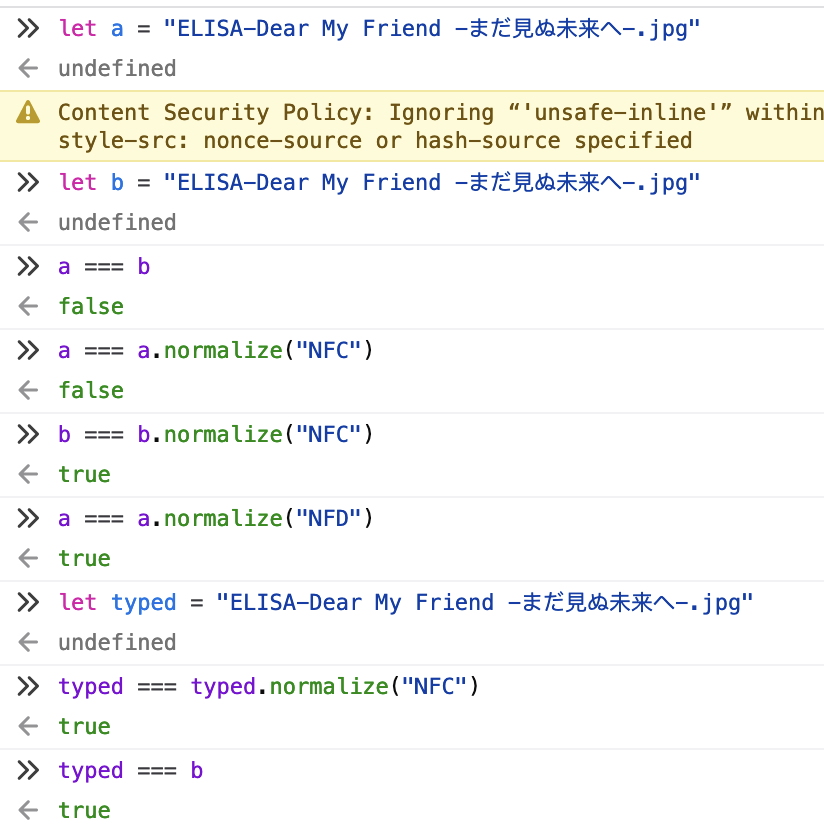
因此我们可以在代码中这样操作,就可以把字符正规化后用于比较:
let a = "ELISA-Dear My Friend -まだ見ぬ未来へ-.jpg"
a = a.normalize("NFC")那么为什么会有这样的四种正规形式呢,它们分别应该在什么时候用,根据我的总结,
- NFC 正规形式就是通常输入法打出来的形式
- NFD 正规形式通常用于希望去掉标号来排序的场景,比如如果希望 Å 排在 B 的前面,就可以转换为 NFD 正规形式再排序
- NFKC 正规形式和 NFKD 正规形式在 NFC 和 NFD 的基础上,所有字符都会被转换为半角标准形式。包括但不限于全角标点如
…变成...,日语全角英文如Future变成Future,以及合字拆分成单字如ff变成ff。
参考资料:
- Unicode等價性
- Difference Between NFD, NFC, NFKD, and NFKC Explained with Python Code
- 《JavaScript 高级程序设计(第4版)》