从 Gatsby 开始的异世界生活
- 0. 导言
- 1. 为什么选择 Gatsby + Strapi
- 1.1 对比其他解决方案
- 1.2 我的需求
- 1.3 Gatsby/Strapi 的优势/劣势
- 1.4 小结
- 2. 简单介绍 Gatsby
- 2.1 什么是 GraphQL
- 2.2 Gatsby 工作流程
- 2.3 Gatsby APIs
- onCreateNode
- createPages
- sourceNodes
- 2.4 本例中使用的 gatsby 插件
- 2.5 MDX
- 3. 关于网页性能优化的心得
- 3.1 综合
- 3.2 图片优化
- 3.3 字体优化
- 3.4 关于 PWA 和 Service Worker
- 4. 新世纪的前端
- 什么是 Web Component?
- 那么新框架是做什么的呢
- 体积
- 兼容性
- 性能
- 组件上下文和依赖注入
0. 导言
我要收回上一篇文章里的言论,Gatsby 真香。
我家博客从最初开始写的时候用的是 WordPress,这几年来一直想换一套方案,最近终于找到了一套满意的方案,并且有时间实施这套改造了。为了写文章先写一套主题,然后主题一写好几年,文章还是没有,我就是这样的。
最主要的,我还要感谢这两年的积累。去年我写那个 WordPress 主题的时候,Gatsby V2 才刚刚释出,社区也还不像现在这样想要的好用的插件几乎都有。而现在,能用上这么可心的解决方案,实在是一件令人雀跃的事情。
这篇文章主要记录本次博客改造遇到的问题,以及分享这些天我学到的一些知识。
1. 为什么选择 Gatsby + Strapi
1.1 对比其他解决方案
我们先来列举一下现在个人博客都有哪些解决方案:
※ 有数据库的后端+后端动态渲染类
典型的比如 WordPress,Typecho,这些东西你要运行一个有数据库的后端,在请求的时候后端负责将页面渲染出来,是最传统的一种。总结特点如下:
- 文章等数据存储在数据库中
- 路由为后端动态路由,是引擎核心的一部分
- 自带评论系统
- 自带管理后台
- 主题以插件的形式随后端一起运行
※ 基于模板的静态渲染类
Hexo,Jekyll,Hugo 都属于这类,这些东西在部署的时候运行一个命令,把静态网站生成出来,此后你就可以扔到一个静态托管的网站上了。特点如下:
- 文章以 Markdown 文件形式存储,日期等数据放在 frontmatter
- 运行时生成静态网站
- 需要一套模板,称为“主题”
- 只能使用外站评论系统,如 DISQUS
- 没有管理后台
※ 基于现代前端的静态渲染类
Gatsby 就属于这一类,这类方案在运行的时候,产生一个静态网站,每个 HTML 文件都经过了预渲染。在用户浏览器登陆这个网站的时候,看到的是提前渲染好的内容。此后,网站以 SPA 的形式运行,加载其他页面时都是由 JS 拉取数据 + 前端 DOM 渲染的方式呈现。这类方案是用同构的代码同时编译出前端和预渲染的网页。
和 GatsbyJS 同属于这一类的还有 VuePress,以及 Saber.js。
※ 使用动态后端+手撸前端
本次改版之前我用的方案就可以归类为这种。特点是拥有“有数据库的后端”那一类的特点,并且是前后端完全分离,前端为独立的 SPA。前端显示出来以后通过 API 从后端拉取数据。也就是说后端用动态博客引擎,前端是自己写的网站。
1.2 我的需求
为什么我选择 GatsbyJS,是因为 Gatsby 完美地满足了我几乎所有的需求。这一节主要解释我有哪些“硬”需求使得我不得不使用 Gatsby。
※ 想要一个管理后台
我曾经尝试过 Jekyll 和 Hexo,可是觉得体验不是很好。原因是,
- 通常这些软件使用的版本控制工具都是 git,可是 git 是一个代码的版本控制工具。用它来管理文章是不合适的。当你写完一篇文章,可能会发现有一些错误,此时你进行一些小的修订,就会产生一条 commit。如果你这篇文章改了好几次,就会有很多 commit-push 记录,很烦,而且会污染 profile 页面,污染时间轴。
- 还是 git 的问题,像 hexo 这种东西,主题和文章在一个大仓里,你要修改页面上的一些东西就需要改主题。代码和文章放在一个版本控制系统下管理,这让我这种有洁癖的人是有些不舒服的
- 不能随时随地。没有管理后台,如果你不是用自己电脑的话(用手机或者别人电脑),就得跑到 GitHub 上去写你的文章,感觉就像在临时修什么 bug 一样,心情很不好。
以上这些都不是什么不能解决的问题,但是总会让人感到不舒服,不舒服多了就不想写文章了。
※ 需要路由平滑切换
也就是需要使用 History API 的前端路由。为什么这点这么重要呢?因为我希望在博客上加入背景音乐。以前我的博客上,即使有音乐,也是某篇文章下有音乐,这样读者读完这一篇以后如果切换了路由,音乐就没法继续播了(网页跳转了)。如果读者想把音乐听完,就只能一直在这个页面上等着。
这种体验很糟糕,我希望在网站上的音乐播放器,能像系统的音乐播放器一样,只要用户还留在这个网站,它就一直存活着。
要实现这个的前提是,需要使用 History API 的前端路由。前两种固然可以,但是需要主题的支持。而事实上,大部分的主题都是不支持的,此其一。其二,即使支持,十有八九是 pjax。pjax 是一种古老技术,它很脏,请求了很多没用的东西;第二 jQuery 什么的依赖复杂版本复杂,维护成本很高;第三,涉及大面积的 DOM 操作,效率不高。其三,你可以自己写一个带 pjax 甚至 SPA 的主题,但是既然是主题就必须在它的框架下,你可能需要用一些奇怪的姿势,并且如果你的前端需要打包编译,源代码管理也很麻烦。
因此这几乎决定了我只能选择拥抱现代前端技术。
※ 需要良好的 SEO
“手撸前端” 最大的问题就是它的 SEO 问题难以解决。即使是世界上最好的搜索引擎,唯一号称能爬 SPA 的谷歌,也没索引到我的几篇文章。其他搜索引擎像百度、必应更是惨得连摘要都没有,就一个标题一个网址。
前端界为了解决这个问题提出了服务端渲染(SSR),而像 Gatsby、VuePress 等正是结合静态渲染和 CMS 的解决方案。
1.3 Gatsby/Strapi 的优势/劣势
此外,Gatsby 和 Strapi 还有一些出人意料的地方,让我觉得实在是太完美了。
※ Gatsby 给的不是一个框架,而是 Node API
很多静态博客引擎,比如 Hexo,它会给你一个框架,有几种页面:Index 是一种,Post 是一种等等,每种模板会给你注入一些博文的数据,然后你在此基础上,可以设计每个页面的主题。又比如 VuePress,它主要是为文档而生,规定你标题就要分这么几级,文件夹是一级、文章是一级、再加上各级标题,按照这个框架来显示。
而 Gatsby 则是给 API:创建页面的 API,拉取数据的 API,查询数据的 API。有了这一套 API 以后,你可以自由地组织你的网站,页面的路由随你定(不是用有限的几种配置方式,而是编程创建的),数据来源也可以有无数种(可以来自本地的 Markdown 文件,也可以来自某种博客后端),数据类型也不一定必须是博文(可以是任何类型,任何后端返回的数据结构,你都可以通过这一套 API,整合到你的网站上)。
因为我们的博客是两个人合写的,所以我需要一些针对我们两个人使用的情景的设计,而 Gatsby 让这些成为了可能。比如说我的个人动态页,合并了【我】写的文章和我的 Twitter 两种数据源,这使用 Gatsby 提供的 GraphQL API 通过一个自定义查询很轻松就可以做到。把某些文章设置为私有,添加一些特殊的固定页面,这都很简单,因为查询是自定义的。
※ Strapi:可以自定义模型的 CMS
Strapi 是用 Node 开发的一款 CMS。得益于使用 MongoDB 作为它的数据库,Strapi 允许用户通过管理后台创建模型。创建模型的过程就像关系型数据库一样,可以添加多个字段(包括富文本字段),添加模型关联(一对一、一对多、多对一、多对多)。创建完模型以后管理后台会自动出来根据你创建的模型组织的添加/修改一条记录(文档)的编辑页面。
这有什么好处呢?好处非常的大,我这相当于一个自己可以扩展的后端,我可以建立自己的数据类型(而不仅仅只是文章),比如说:我可以把友情链接做成一种模型,我就可以通过后端来管理站上的友链;或者我把音乐作为一种模型,我就可以通过后端来添加/修改站点的背景音乐播放列表。
使用博客引擎它提供的功能不一定总是切合你的需求,但是这样自己定义的数据类型一定总是切合你的需求。
Strapi 通过 REST API 提供所有模型数据的增删改查操作。同时也提供 GraphQL API(现在可能还没做好)。Strapi 还提供官方的 Gatsby 插件,它通过 Strapi 的 REST API 拉取数据,然后在 Gatsby 这里转换为 GraphQL Schema。
※ 拥抱 React 社区,享受 MDX
一年前我在了解 Gatsby 的时候,MDX 项目才刚刚起步,issue 很多。而现在,MDX 项目已经发展的很大了,成为了 Gatsby 官方插件,而且兼容了所有 gatsby-remark 的插件。
什么是 MDX?最初有人提出在 Markdown 中使用 React 组件的设想。这其实不是什么新鲜事,因为早在 MDX 能用之前,Vue 社区的 Docute 和 Peco(现在改名叫 Saber.js 了)就已经实现了在 Markdown 中引入 Vue 组件的功能。
MDX 允许你在 Markdown 中使用 React 组件,例如我可以引入一个自定义的播放器,在我的 Markdown 文章里,加上 <MusicPlayer src="1.mp3" />,就可以在这里渲染出一个我自己写的 React 组件来。
虽然 Vue 那边也具备这样的功能,但是很遗憾并没有能够发展出 Gatsby 这样繁荣的社区来。我觉得这正是 React 社区的强大之处,它的每个包都只专注于做好自己的一点小事,做好了以后别人就可以拿去用,而不是“我写个框架什么功能都有,一句话能写个 Hello world”。这样每个人都做一点,每个人都可以挑自己喜欢的组合用,人越来越多,社区就壮大了。
※ 存在的问题
- 学习曲线比较陡:首先你得是个 React 玩家。然后你还得简单了解一下 GraphQL,然后还得把它的文档老老实实地看一遍,跟着教程走一遍,才能搞懂这是在干什么。所以为了帮助大家入门,本文的后面也花了一些篇幅来介绍 Gatsby。
- 和 React 捆绑,如果你是个 React 黑或者 Vue 吹之类的恐怕想用就只能换到 React。
- 还是存在一些迷之 bug,比如 gatsbyjs/gatsby#issue-11109,很烦。
1.4 小结
如果你还在纠结使用什么博客引擎的话,我十分地安利 Gatsby,它无论从可维护性、代码整洁程度、SEO、创作体验、用户体验、性能哪一方面来讲,都是极佳的,无论从哪一方面来讲,都是目前世界上最好的博客解决方案。
也许比起像我这样使用动态后端你更喜欢使用静态 Markdown 文件,但是 Gatsby 你一定要去尝试一下。
2. 简单介绍 Gatsby
你可能会感到有些困惑,就像当年的我一样。在这篇文章里我打算带读者了解一下,Gatsby 是怎么工作的?为什么要使用 GraphQL?GraphQL 有什么用?我如果要某一个功能能否借助 Gatsby 来实现?
2.1 什么是 GraphQL
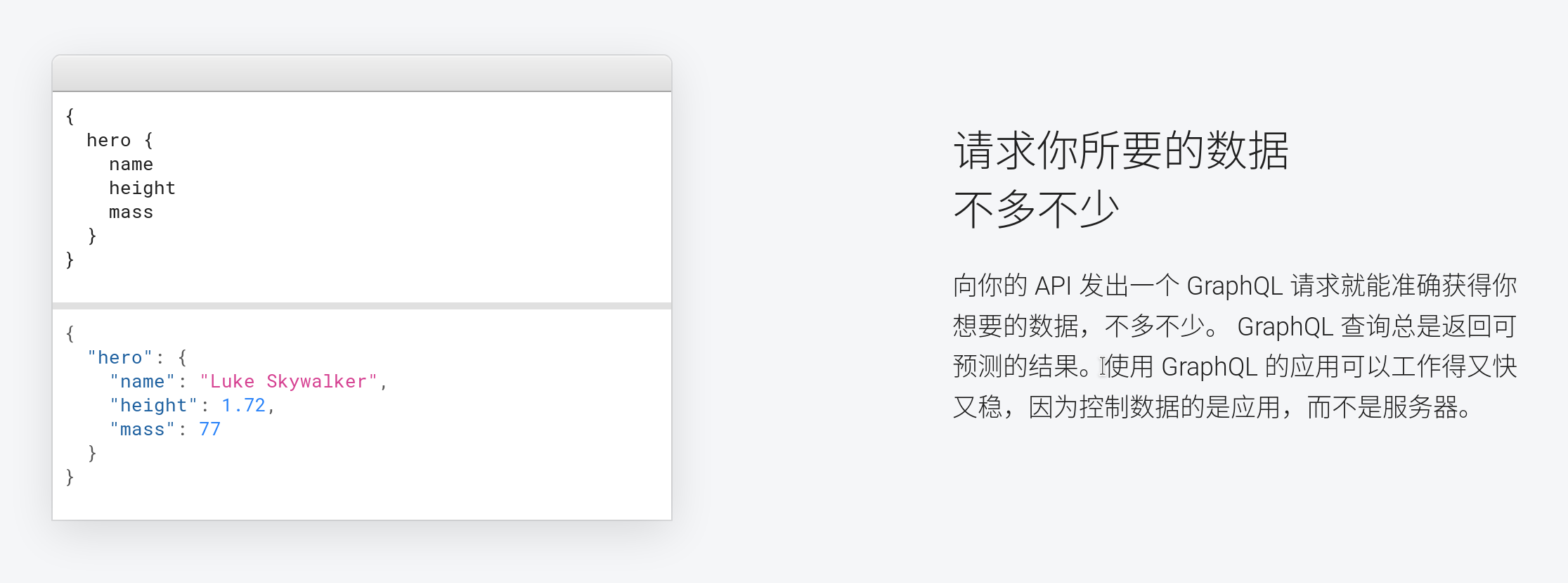
GraphQL 一张像图一样的 API,它不像 REST API 有很多不同的 endpoint,它整个 APP 只有一个接口。在使用这个接口的时候客户端向服务器请求你所需要的数据:可以是任何模型,任何字段。
RESTful 的 API 是关于资源的,每个 endpoint 都代表一个资源。譬如,/posts 就是文章,/comments 是评论,那么你要拉取一篇文章下的评论,你要先请求 /posts 再请求 /comments —— 至少按照规范来讲应该是这样设计。
你发现了吧,RESTful 其实很蠢的。真正的 API 没有人会这么搞,太难用了。大家学习的大多都是 HTTP 动词语义,路由语义,至于这个严格必须扮演“资源”的角色,在实践中是很尴尬的。
而 GraphQL 则解决了这一问题,它允许你通过模型关联直接取出所有你需要的字段。比如上面的梨子,你就可以写
query {
post {
content
comments {
content
}
}
}就可以直接查询出这篇文章的内容和下面所有评论的内容。
世人对 GraphQL 多有误会,一种误会是,GraphQL 的好处都让前端占去了,后端巨麻烦。其实并没有,使用 HTTP JSON API,一个良好的设计也不会白白浪费许多 HTTP 请求,不但增大 Web 服务器的压力,增大数据库查询的压力,用户体验也不好。同样后端也需要把数据组合好传到前端来,而前端用 Apollo 也不比用 fetch 轻松到哪去。所以作为后端没有必要仇视 GraphQL,我觉得还是很值得学一学,如果开发新项目的话可以考虑用一用的。
另一种误会是 GraphQL 和 REST(HTTP JSON API)相比,没有显著的好处,所以不可能取代现有的架构。事实上,GraphQL 和 HTTP JSON API 并不是必须是用其中一个的关系,每个微服务提供自己的 RESTful API,整个系统再向外暴露一个统一的 GraphQL API 是典型的应用场景(Gatsby 也是这样的)。GraphQL 可以和 REST API 结合使用,并且它们配合的很好。
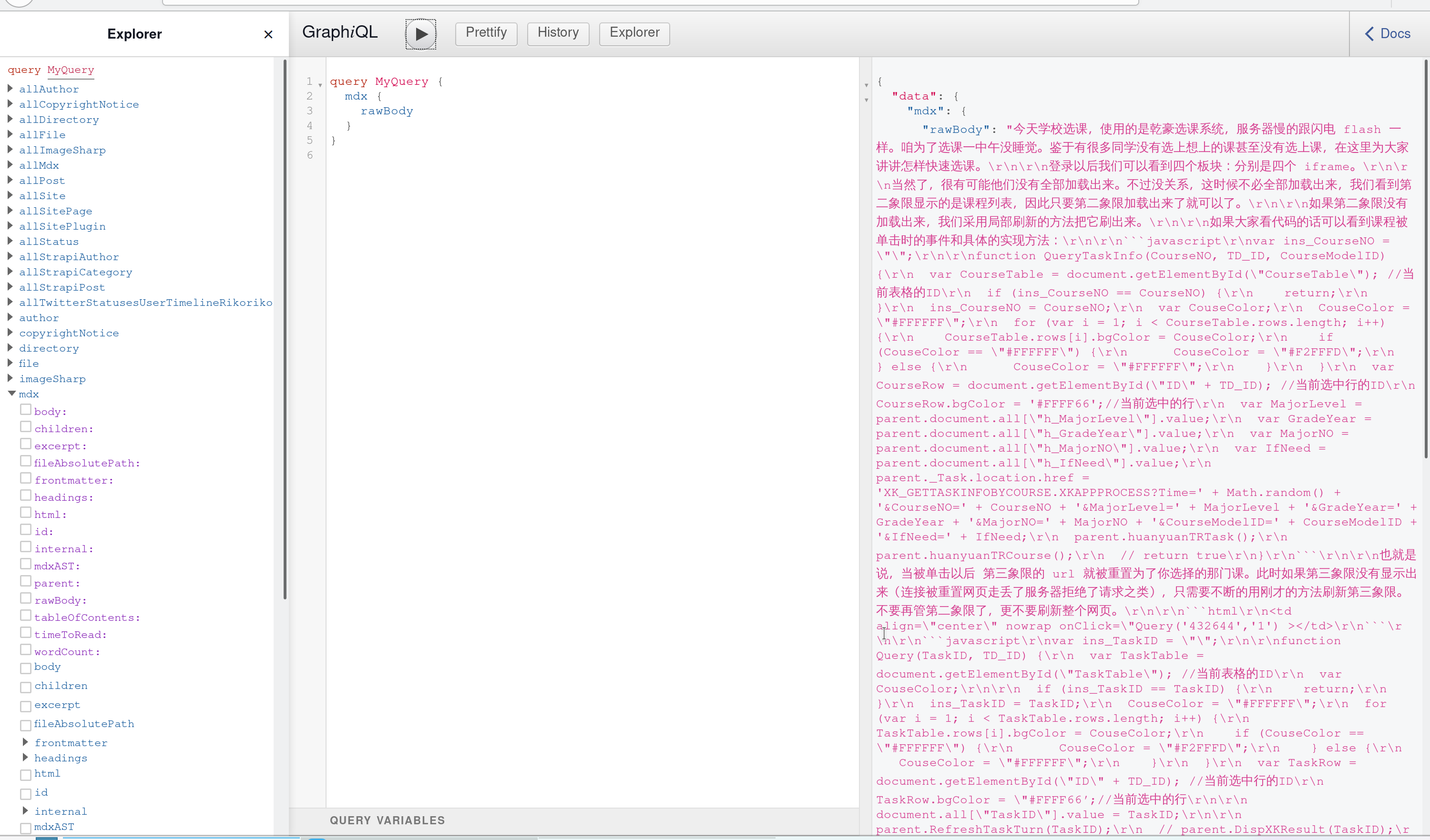
GraphQL 提供了一个调试工具 GraphiQL,如图。你不再需要打开 Postman,然后自己想想要填上什么地址什么字段,然后测试一下后端接口是不是好用。打开 GraphiQL,左边的窗口会显示可以请求的资源、参数和字段,轻轻勾几下,点播放,你的请求就完成了。
2.2 Gatsby 工作流程
下图为我画的 Gatsby 工作示意图。
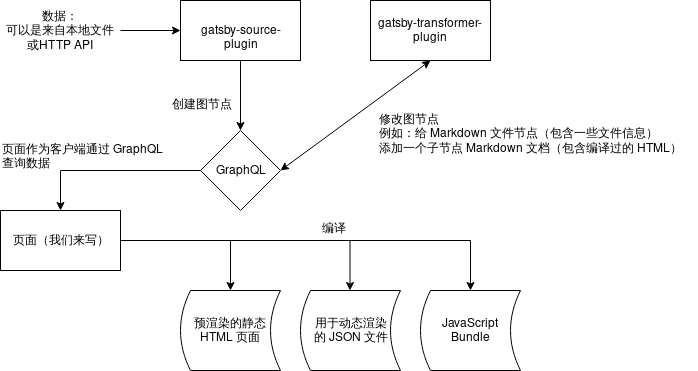
运行时,首先所有的 gatsby-source-plugin 先从外部拉取数据,可以是本地文件,可以是 Strapi API,Netlify API,Twitter API 都可以。拉取完了以后,按照插件写的逻辑,创建一些 GraphQL 节点。
然后 gatsby-transformer-plugin 完成第二步,对数据的加工处理,可能是对现有节点做一些修改,或者加一些节点,或者加一些节点再加一些和现有节点的关系。典型的 Markdown 的解释就是这一步做的,gatsby-transformer-remark 把 Markdown 编译为 HTML,gatsby-plugin-mdx 则是编译为一段 JavaScript。它们把自己创建的新节点作为 child 挂在原来的 Post 节点上。
所有的插件都运行完,所有的数据就都准备好了。此时如果是启动了 dev server,相当于是开了一个已经有数据了的 GraphQL 后端,你在改前端的同时,webpack 会直接 hot reload。但是总的数据是不会变的了(即使后端更新了),你只需要调试你的页面如何通过 GraphQL 查询数据,以及你的视图部分就可以了。
如果是 production build,则会直接编译 JavaScript 模块,打包程序,然后运行 SSR 生成预渲染的 HTML 页面和用于切换页面的 JSON 文件。
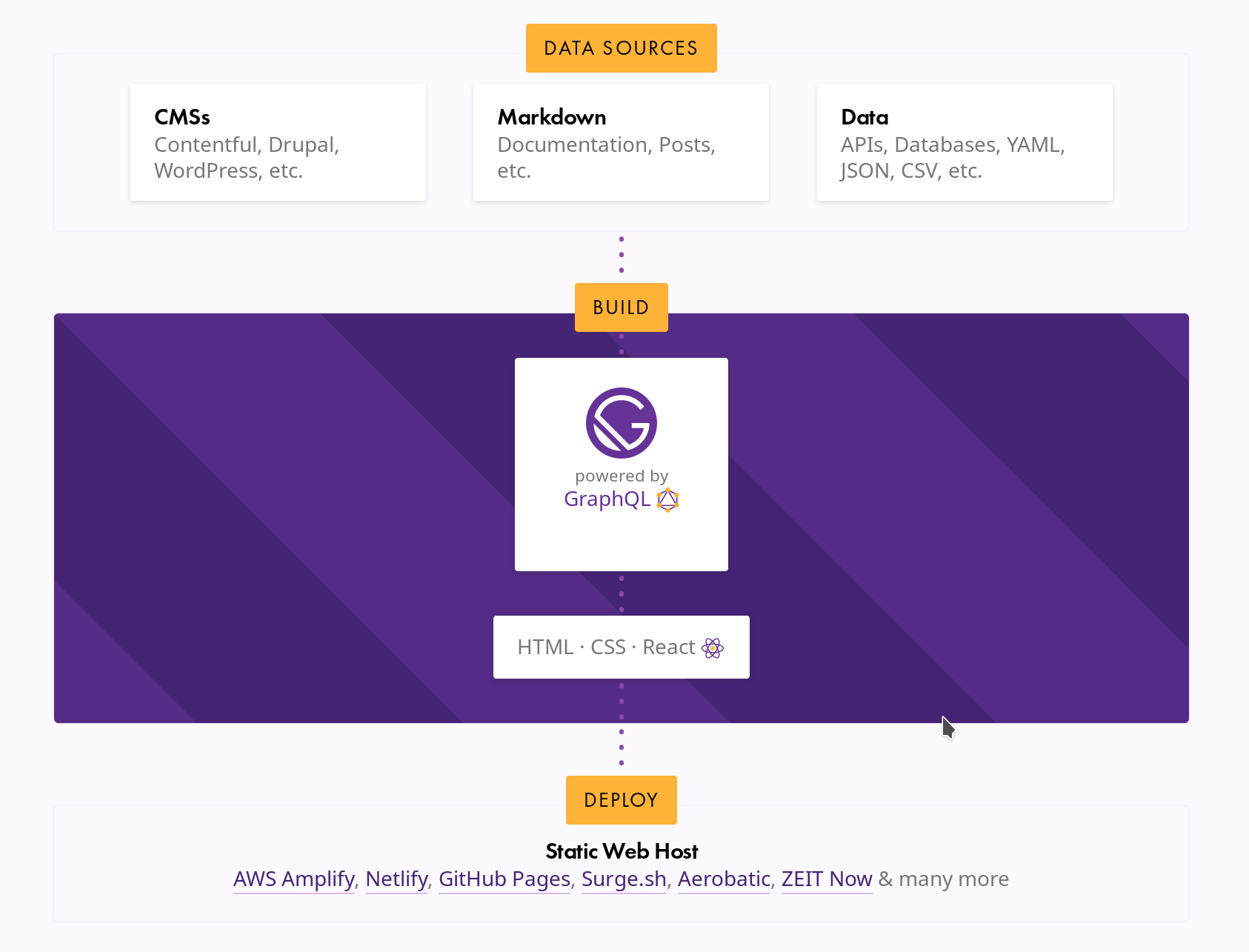
图为 GatsbyJS 官网展示的示意图。
2.3 Gatsby APIs
列举一些 Gatsby 的 API,这样读者能够更加理解这些插件是怎么(通过 Gatsby 提供的 API)工作的。
onCreateNode
当一个图节点被创建时会触发此事件。
示例: 下面是对于每个 Strapi Post,创建一个新节点,声明他的类型是 'text/markdown'(这样才能被 gatsby-plugin-mdx 处理)
// gatsby-node.js
exports.onCreateNode = ({ node, actions }) => {
const { createNode, createNodeField } = actions
if (node.internal.type === 'StrapiPost') {
await createNode({
...node,
id: node.id + '-markdown',
parent: node.id,
internal: {
type: 'Post',
mediaType: 'text/markdown',
content: node.content,
contentDigest: createContentDigest(node),
},
})
return
}
}createPages
创建一些页面。
示例:以下是每页 10 篇文章,创建出所有 /pages/{页码} 的页面和首页 /
// gatsby-node.js
exports.createPages = ({ graphql, actions }) => {
const { createPage } = actions
graphql(`
query {
allPost(limit: 10) {
pageInfo {
pageCount
perPage
}
}
}
`).then(result => {
for (let i = 1; i <= result.data.allPost.pageInfo.pageCount; i++) {
createPage({
path: `pages/${i}`,
component: path.resolve(`./src/templates/2645lab/index.tsx`),
context: {
skip: (i - 1) * result.data.allPost.pageInfo.perPage,
limit: result.data.allPost.pageInfo.perPage,
},
})
}
createPage({
path: `/`,
component: path.resolve(`./src/templates/2645lab/index.tsx`),
context: {
skip: 0,
limit: result.data.allPost.pageInfo.perPage,
},
})
})
}sourceNodes
创建一些图节点。
示例:通过 createRemoteFileNode API(由插件 gatsby-source-filesystem 提供)下载 siteMetadata 中的作者头像到本地
// gatsby-node.js
const { createRemoteFileNode } = require('gatsby-source-filesystem')
const { siteMetadata } = require('./gatsby-config')
exports.sourceNodes = async ({
actions,
store,
cache,
createContentDigest,
}) => {
const { createNode } = actions
for (const author of siteMetadata.authors) {
try {
await createRemoteFileNode({
parentNodeId: `author-${author.name}`,
url: author.avatarUrl,
store,
cache,
createNode,
createNodeId: () => `${author.name}-local-image`,
})
} catch (err) {
console.error('avatar image download ERROR:', err)
}
}
}2.4 本例中使用的 gatsby 插件
基础插件:
- gatsby-plugin-typescript TypeScript 语言
- gatsby-plugin-tslint TSLint
- gatsby-plugin-stylus Stylus CSS 预处理语言
- gatsby-plugin-emotion Emotion (CSS-in-JS 库)
源插件:
- gatsby-source-filesystem 用于把本地(或从网络上下载来)的文件转换为节点
- gatsby-source-strapi 用于把从 Strapi API 下载的数据转换为节点
- gatsby-source-twitter 用于把从 Twitter API 下载的数据转换为节点
转换插件:
- gatsby-plugin-mdx 用于编译 MDX
- gatsby-plugin-sharp & gatsby-transformer-sharp 用于压缩图片
Remark 插件:
- gatsby-remark-external-links 用于给文章中外站的链接加上 target="_blank"
- gatsby-remark-images 用于压缩文章中的图片
- gatsby-remark-mathjax 用于显示数学公式
- gatsby-remark-prismjs 用于高亮代码块
其他增强插件:
- gatsby-plugin-react-helmet 用于切换路由时切换标题
- gatsby-image 用于图片的提前占位和模糊预加载
- gatsby-plugin-disqus 用于显示 DISQUS 评论
- gatsby-plugin-feed 用于生成静态 rss
- gatsby-plugin-manifest 用于生成 manifest
- gatsby-plugin-nprogress 用于顶部切换路由时的进度条
- gatsby-plugin-remove-serviceworker 用于卸载之前网站上的 Service Worker
2.5 MDX
简单讲一下 MDX 的原理。
正常如果使用 gatsby-transformer-remark 这个插件的话,在 GraphQL 查询中会有个字段叫 html,然后把这 html 渲染到页面上就可以了,像这样
// CSS Module
// import styles from './post.module.styl'
<div
className={styles.post}
dangerouslySetInnerHTML={{ __html: this.props.data.post.childMarkdownRemark.html }}
/>而使用 gatsby-plugin-mdx 的话,这个字段变成了 body,如果直接打印会是一段编译过的 JS 代码。
渲染的时候使用 gatsby-plugin-mdx 提供的 MDXRenderer 即可
// import { MDXRenderer } from 'gatsby-plugin-mdx'
<MDXRenderer>{this.props.data.post.childMdx.body}</MDXRenderer>可以加上一些全局组件,这样在 MD 文章里不需要 import 就可以直接引用这些组件:
// import { MDXProvider } from '@mdx-js/react'
// import { MDXRenderer } from 'gatsby-plugin-mdx'
// import Alert from '../../components/alert'
// import Hr from '../../components/hr'
<MDXProvider components={{
hr: Hr,
alert: Alert,
}}>
<MDXRenderer>{this.props.data.post.childMdx.body}</MDXRenderer>
</MDXProvider>MDX 号称兼容 gatsby-transformer-remark 的所有插件,比如用于代码高亮的 gatsby-remark-prismjs。可是它加载数学公式有问题(gatsbyjs/gatsby#issue-16983),可以利用 MDX 的特性,利用 React JSX 组件来解决,但是很脏(因为是 JS 字符串需要把所有的 \ 都转义成 \\)。
此外 gatsby-remark-images 这个插件没有办法下载远程图片(gatsbyjs/gatsby#issue-16780),这样像我这种用 CMS 后端的或者用图床的就没法用了。
3. 关于网页性能优化的心得
3.1 综合
在上次写主题的时候,我给 Header 写了十分复杂的动画,那个动画很卡,尤其在手机上。而这次,我则把重点放在性能上。我以前觉得现在计算机这么先进,应该不会有太大问题;而现在则觉得,虽然区别不大,一个很轻,响应很快,加载很快的网页还是更能给人一种特别好的感觉。因此在本次的主题设计上,我尽可能地避免了复杂的阴影、动画,力求在美观的同时最大限度地简洁。
3.2 图片优化
通过这次的实践,我认识到图片优化的一个很重要的原则就是,要避免网页串位置,那样体验很不好。像我以前还在文章的上面那里放一个警告框,警告框一出来所有文章都会往下移一下,实在是愚蠢至极。
有了这个原则,那么首先可以做的就是,把不重要的图都用 div + background-image 属性来代替,设置 div 的宽度和高度。这样图片在加载的过程中就不会引起网页布局的浮动。什么是不重要的图?就是一些背景啊,头像啊什么的。因为这样做有个缺点,用户就不能右键保存/在新标签页打开这张图了。如果这个图很重要,比如说是一些推文的色图、立绘之类的,用户就要骂了。
那这种时候怎么办呢,仍然使用 img 标签,把 position 设置成 absolute,然后再在相同的位置放一个 div,设置宽高比和 img 一样,这样无论网页和图片怎么缩放它们两个都是叠在一起的。图片还没有加载出来之前,它的位置也会由后面的 div 占好。如何设置宽高比?设置 height: 0; padding-bottom: ${height / width}; 就可以了。
不过使用 gatsby 的话,其实不需要自己去做这些,gatsby-image 不仅能完成占位,还可以压缩一张小图先加载,再加载大图(blur-in 效果),很漂亮。
3.3 字体优化
说起字体优化,少不了两个库,font-spider 和 fontmin。fontmin 提供了压缩 CJK 字体的方法,只需要传入字体文件和需要用到的文字。而 font-spider 则是通过解析 HTML 文件引用和内联的 CSS,找到每种字体都用了哪些文字,然后使用 fontmin 进行压缩。
然而缺点是,font-spider 只能解析静态的 HTML,通过 JS 动态渲染的文字它无法识别。不过好在 Gatsby 已经为我们执行了预渲染。所以说在 Gatsby 项目中用 font-spider 一点问题都没有!怎么使用的,很简单,把 package.json 中 build 的脚本改成这样就可以了
gatsby build && cd ./public && font-spider --no-backup --map "/static","./static" *.html3.4 关于 PWA 和 Service Worker
以前为了追逐潮流,每次我搞一个应用就给它开 PWA。但是现在我发现,PWA 体验其实并不是那么好,怎么说呢
你并不需要 PWA:PWA 主要是用于离线场景的,你希望用户离线的时候也能使用的 APP,不会因为断网了网页就打不开了。可是像我们这样高度依赖网络的应用,为什么需要用户离线也能打开呢?
PWA 更新缓慢:Service Worker 自己有它的一套缓存策略。那么我作为一个博客,为什么不直接让用户每次访问我的网站,都下载最新的呢?这样不是更好。
PWA 有后遗症:因为我以前这个网站开过 Service Worker,所以我现在不能直接把 service-worker.js 删掉,即使是我不用它了。因为如果 service-worker.js 没法更新,它就会一直存在在用户的浏览器里,阴魂不散,用户永远也看不到更新的主题和文章了。好在这个问题还没那么难解决,上网查查就明白了,而且 Gatsby 还专门提供了解决此类问题的插件 gatsby-plugin-remove-serviceworker。
仅在 Chrome 浏览器下表现独特:由于 Google 控制了安卓,所以你如果用 Chrome 浏览器的话,可以把 PWA 保存成一个应用,这个应用图标就跟 native 应用没什么区别,再加上应用是全屏的,体验的确不错。但是如果你用其他浏览器,完全没有这样的待遇,保存了就像个浏览器书签,再打开还是打开的浏览器,没什么特别了不起的。同样的还有 themeColor 的 meta 标签,只能改变手机 Chrome 下的标签颜色,对桌面 Chrome 和其他浏览器都完全不起作用。像这样的非标准的标准,我越来越懒得在上面费心了。
4. 新世纪的前端
最近,我在 GitHub 上发现有朋友点赞腾讯的开源前端框架 omi,我去大致了解了一下,它是使用最新的 Web Component API。借此机会,我了解了一番使用 Web Component 的新框架们,这里也想向本文的读者介绍一下。
什么是 Web Component?
它是通过一个 JS 类,加上启用了 Shadow DOM,再加上浏览器的 customElement API,就可以创建出一个类似于 React、Vue 或是 Angular 的 Component 封装。这个 Component 有自己的属性,方法,模板和只作用于这个组件内部的 Style。
下面这段摘自阮一峰老师的博客,这就是一个简单的 WebComponent。但是他那篇博客有问题,可能是在他写了之后标准又更新了,会出错,我稍微改了一下。
class UserCard extends HTMLElement {
constructor() {
super();
var image = document.createElement('img');
image.src = 'https://semantic-ui.com/images/avatar2/large/kristy.png';
image.classList.add('image');
var container = document.createElement('div');
container.classList.add('container');
var name = document.createElement('p');
name.classList.add('name');
name.innerText = 'User Name';
var email = document.createElement('p');
email.classList.add('email');
email.innerText = 'yourmail@some-email.com';
var button = document.createElement('button');
button.classList.add('button');
button.innerText = 'Follow';
container.append(name, email, button);
this.attachShadow({mode: 'open'});
this.append(image, container);
}
}
customElements.define('user-card', UserCard);使用的时候只需要像普通的 HTML 标签一样用就可以了
<user-card></user-card>那么新框架是做什么的呢
以时下最为流行的基于 Web Component 框架 LitElement 为例,它提供一个基类,你可以在自己定义的子类中实现类似于 React 的 render() 方法。同时可以用声明式的方法来定义 css,这样 css 和 template 都解决了,用起来就跟用 React 感觉差不多了。
一个简单的 LitElement Component:
import { LitElement, html, css } from 'lit-element';
class MyElement extends LitElement {
static get styles() {
return css`
:host {
display: block;
}`;
}
render(){
return html`
<div>
<p>A paragraph</p>
</div>
`;
}
}
customElements.define('my-element', MyElement);体积
这些框架的体积都非常小,按照官方宣传的,gz 之后的体积 LitElement 只有 5~6K,omi 则是 8K,远远地小于 Vue 或者 React+ReactDOM 的体积。
兼容性
由于它们这些类都是继承自 HTMLElement,所以这些组件并不是框架依赖的。写好之后可以在任何框架中集成——唔 虽然这些框架都以此为骄傲,omi 更是大肆宣传它的这一点,但这其实是句废话。难道我不能在一个 Vue 项目中用 React 组件吗,当然可以,只不过 50~60K 的成本太高了。而这些框架的优势在于他们的体积很小,所以也许导入到别的项目里用的人不会觉得很难受吧。
关于浏览器兼容性,基本主流的浏览器在十个版本前就已经支持了,所以如果你不需要考虑老的浏览器的话,比如我的博客,那就没什么问题。老的浏览器的话需要运行 Polyfill,Vue 的网站上说这 Polyfill 十分缓慢,所以如果你需要兼容旧浏览器,还需要慎重考虑。
性能
要解释这些新框架和传统虚拟 DOM 框架的性能区别,我们就要先来复习一下,为什么使用虚拟 DOM?没错,为了快。假设你在开发一个复杂的数据展示应用,现在很多数据发生了改变,你可以选择 A. 用 jQuery 一个一个地把需要改变的地方的 DOM 更新了。但是这样写起来很麻烦,代码很丑很难维护。B. 直接把整个 DOM 重新生成,重画一遍。但是这样开销很大。怎么办呢,人们就提出了虚拟 DOM。在 JavaScript 中模拟一颗 DOM 树,数据改变时先重算这颗虚拟 DOM,然后和真实的 DOM 做比较,把更新了的部分更新到 DOM。这就是虚拟 DOM 框架所完成的工作。
那么新的,没有使用虚拟 DOM 的框架,就一定比传统的虚拟 DOM 框架(如 React、Vue)慢吗?未必。这里有篇文章,讲的是 HyperHTML 的实现原理。LitElement 用的是 LitHTML(类似于 HyperHTML),所以我觉得上面那篇文章基本可以帮助我们理解它的原理。大概就是,在解析模板的时候就已经确定了哪些部分是可能会被更新的,然后在 state 改变的时候只需要去更新 DOM 中的那些部分就可以避免 DOM 开销,同时并不需要维护一颗虚拟 DOM 树。这里有篇文章做了 LitElement 和 React 对比,性能不输 React。
组件上下文和依赖注入
我们知道,React 是提供了组件的上下文的,利用这个上下文,可以实现路由容器或者依赖注入。比如我们都知道注入 Redux 的 store 就这样写:
import React from 'react'
import { render } from 'react-dom'
import { Provider } from 'react-redux'
import { createStore } from 'redux'
import todoApp from './reducers'
import App from './components/App'
let store = createStore(todoApp)
render(
<Provider store={store}>
<App />
</Provider>,
document.getElementById('root')
)这样在 App 中都可以访问到这个 store。
而 LitElement 并不提供这个上下文,LitElement 官方指引上推荐的使用 Redux 的方法也没有使用依赖注入,而是引用了静态常量:
// store.js
export const store = createStore(
reducer,
compose(applyMiddleware(thunk))
);import { LitElement, html } from 'lit-element';
import { connect } from '@polymer/pwa-helpers/connect-mixin.js';
import { store } from './store/store.js';
class MyElement extends connect(store)(LitElement) {
static get properties() { return {
clicks: { type: Number },
value: { type: Number }
}}
render() {
return html`...`;
}
// If you don't implement this method, you will get a
// warning in the console.
stateChanged(state) {
this.clicks = state.counter.clicks;
this.value = state.counter.value;
}
}要实现依赖注入,我在相关 issue 上看到这个演讲,介绍了一种思路,是通过 event 实现 Web Component 的依赖注入,这里推荐给大家。